前言
最近在B站上学习子烁老师的垃圾回收机制篇,讲的很清晰,这里根据自己理解写下笔记加深下印象。
下面主要以垃圾回收基础知识、回收算法、分代回收策略、经典垃圾收集器四个方面展开。
垃圾回收基础
主要回收的垃圾是什么
首先我们要搞清楚我们主要回收的垃圾是什么,这边我们需要了解Java虚拟机内内存是怎么分布的,这些内存分别存储了什么东西,下图是JVM的内存模型:
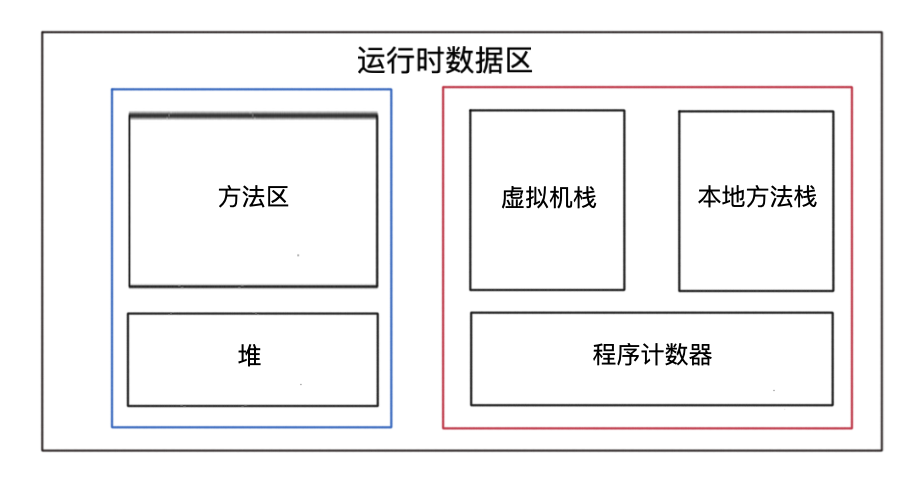
红色框:代表的是线程私有的内存,这些内存随着线程的创建而创建,销毁而销毁。
蓝色框:代表的是线程共享的内存。
方法区:主要存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等。方法区主要回收的是废弃的常量和无用类。
堆内存:就是存放对象实例,几乎所有的对象实例都在这里分配内存。主要回收无用的对象。
了解了上述这些之后我们知道,垃圾回收的主要区域在堆中。
垃圾何时被回收
当一个对象不再被引用了,也就是这个对象在内存中没有人用它的时候,这时候可以被回收。
这边引入一个概念,Java中的引用分为四类:
- 强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象。强引用的创建最为常见一般
Object object = new Object();就是强引用。 - 软引用:如果内存的空间足够,软引用就能继续被使用,而不会被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收。
- 弱引用:只要发生GC就会回收。
- 虚引用:在垃圾被回收时候可以接收一个通知
判断垃圾是否可被回收
判断一个垃圾是否被回收,那么我们就要确定他是否还有用。如何确定是否还有用呢,就是没有任何引用该对象,就说明这个对象是垃圾了,可以被回收。一般判断是否可以被回收,有两种算法:分别是引用计数法和可达性分析算法
引用计数法
引用计数法是通过引用计数器来判断对象是否存在引用,当有地方引用该对象时该对象的引用计数器就会加1,当引用失效就会减1。通过判断该对象的引用计数器是否为0来确定是否可被回收。如下图:
但是我们仔细想想引用计数器他是存在问题的,如果两个无用的对象都引用了对方,那么他们的引用计数都为1,但却是垃圾对象。用了这个算法,GC永远无法回收下图中的A、B对象。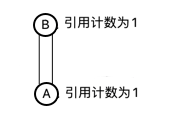
可达性分析算法
该算法为主流GC发现垃圾对象的算法,它通过GC ROOT的对象作为搜索起始点,通过引用向下搜索,所走过的路径称为引用链。通过对象是否有到达引用链的路径来判断对象是否可被回收。
如上图所示,Object1–Object4对GC Root都是可达的,说明不可被回收,Object5–Object7对GC Root节点不可达,说明其可以被回收。
在Java中可以被作为GC Root对象的主要是下面四种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
即使在可达性分析算法中不可达的对象,非回收不可,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历再次标记过程。
标记的前提是对象在进行可达性分析后发现没有与GC Roots相连接的引用链。
第一次标记并进行一次筛选:
筛选的条件是此对象是否有必要执行finalize()方法。
当对象没有覆盖finalize方法,或者finzlize方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行,对象被回收。
第二次标记:
如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为:F-Queue的队列之中,并在稍后由一条虚拟机自动建立的、低优先级的Finalizer线程去执行。这里所谓的执行是指虚拟机会触发这个方法,但并不承诺会等待它运行结束。这样做的原因是,如果一个对象finalize()方法中执行缓慢,或者发生死循环(更极端的情况),将很可能会导致F-Queue队列中的其他对象永久处于等待状态,甚至导致整个内存回收系统崩溃。
Finalize()方法是对象脱逃死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第二次小规模标记,如果对象要在finalize()中成功拯救自己—-只要重新与引用链上的任何的一个对象建立关联即可,譬如把自己赋值给某个类变量或对象的成员变量,那在第二次标记时它将移除出“即将回收”的集合。如果对象这时候还没逃脱,那基本上它就真的被回收了。
原文链接
回收算法
由于JDK对垃圾收集器并没有制定规范,所以各个厂商都采用不同的方式来实现垃圾收集器,下面介绍四种主流的垃圾回收算法。
标记-清除算法
该算法是最基础的收集算法。算法分为标记和清除两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象(标记过程主要是上述的可达性分析算法)。后续的收集算法都是基于这种思路并对其不足加以改进而已。

严重问题:
通过该算法回收的内存,会产生大量的内存碎片,由上图就很好理解,存活对象并不是在一块的,由此产生一块块分散的未使用内存空间,会导致无法申请一个比较大的连续的内存空间。
复制算法
该算法是为了解决标记-清除的内存碎片问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等的复杂情况,只需要移动堆顶指针,按顺序分配即可。该算法逻辑清晰,也运行高效。

严重问题:
该算法必须把内存拆分为两半,意味着原本只需要10G的内存就能跑的程序,现在需要20G内存。需要的内存是原来的两倍
标记-整理算法
由于复制收集算法在对象存活率较高时会进行比较多的复制操作,效率会变低。因此在存活率较高的老年代一般不能使用复制算法。
针对老年代的特点,提出了一种称之为标记-整理算法。标记过程仍与标记-清除过程一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象向一端移动,然后直接清理掉端边界以外的内存。

严重问题:
该算法存在效率的问题,内存变动更加频繁,每次都需要整理所有存活对象的引用地址。
分代收集算法
这个算法没有新创意,只是上面三种算法的一套组合拳一般是把Java堆分为新生代和老年代。

在新生代中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代中对象存活率高、没有额外空间对它进行分配担保,就必须采用标记-清除或者标记-整理算法。
分代回收策略
当前JVM垃圾收集都采用的是分代收集(Generational Collection)算法,在Java堆中新生代默认是占堆的1/3,而老年代默认占堆的2/3
新生代回收
所有新的对象基本都在Eden区中生成,等到Eden区被填满的时候就触发Minor GC,在Eden区中对象的存活率低,于是采用复制算法,将Eden区中存活对象复制到任意一个Survivor区中,再将Eden区清空,就完成了一次Minor GC。具体如下图:
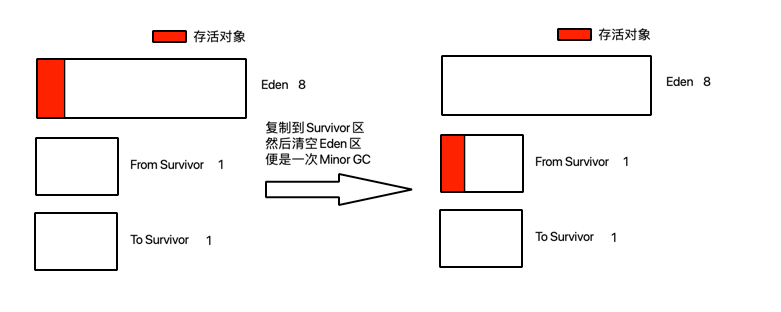
当Eden区再次被填满的时候,需要在进行一次Minor GC,但是之前的Survivor区中的对象不一定都是存活的,也会有一些垃圾对象,他也会在这次Minor GC中被清除。依旧采用的是复制算法,将Eden区和一个Survivor区中的存活对象复制到另一个Survivor区钟,在对另外两个区进行清除。

接下来的每次Minor GC都和上面的流程一样,每次都需要清扫一个Eden区和一个Survivor区。
Q1:对象什么时候从新生代进入老年代?
新生代的每一次Minor GC都会使存活对象的年龄加1,也就是存活对象的复制次数。当年龄到达一个阈值的时候,该对象就会被放入老年代,这个阈值默认是15。
Q2:进入老年代的方式有哪些?
1.如果Minnor GC的存活对象比Survivor区大,那么这些对象会过早老化,直接进入老年带
2.经历15次Minor GC的对象
3.大数组,大字符串等会直接在老年代中进行创建。
Q3:分代年龄可否设置成31?
因为分代年龄在对象中占4位,4位二进制最大是15,因此不能设置成31。
老年代回收
由于老年代的GC频率较低,通常使用标记-整理算法来进行回收,老年代的回收又称为Major GC。
如果有小伙伴,想要一起交流学习的,欢迎添加博主微信。
